TypeORM でページングやカウントするときに生成される SQL とそのパフォーマンスについて考察します。
検証に使うサンプルアプリケーション
実際にサンプルアプリケーションを作って振る舞いを確認します。 本稿で検証するサンプルアプリケーションは次のリポジトリにあります。
調査した環境は次になります。
- TypeORM: 0.2.34
- Node.js: v14.17.1
- PostgreSQL 12.7
環境構築
次のコマンドで構築できます。
$ docker-compose up -d
$ yarn dbinit
詳細は前記事の TypeORM の @RelationId デコレーターとパフォーマンス の環境構築を参照してください。
動作確認用にテストコードも書いていますが、後述する REPL の方がわかりやすいです。
$ env DEBUG=true yarn test --testNamePattern "Distinct"
実際にコードを実行するときにどういった SQL が発行されるかを調べるのに REPL を使います。
$ yarn repl
... (デバッグ用に SQL を出力しています)
... (Enter を入力するとプロンプトが表示されます)
>
検証対象の Entity オブジェクト
Article と User Entity を使います。
Article は数個のカラムと次の関連をもちます。
@ManyToMany@ManyToOne@OneToOne
@Entity()
export class Article extends Base<Article> {
@PrimaryGeneratedColumn()
id: number;
...
@ManyToMany((type) => Category, {
nullable: true,
lazy: true,
})
@JoinTable()
categories: Promise<Category[]>;
@ManyToOne((type) => User, {
nullable: true,
lazy: true,
})
user: Promise<User>;
@OneToOne((type) => Attach, {
nullable: true,
lazy: true,
})
@JoinColumn()
attach: Promise<Attach>;
}
User は次の関連をもちます。
@OneToMany
@Entity()
export class User extends Base<User> {
@PrimaryGeneratedColumn()
id: number;
...
@OneToMany((type) => Article, (article) => article.user, { lazy: true })
article: Promise<Article[]>;
}
4つの関連のパターンに対して調査ができるようにしています。
ER 図
整理のために ER 図は次のようになります。
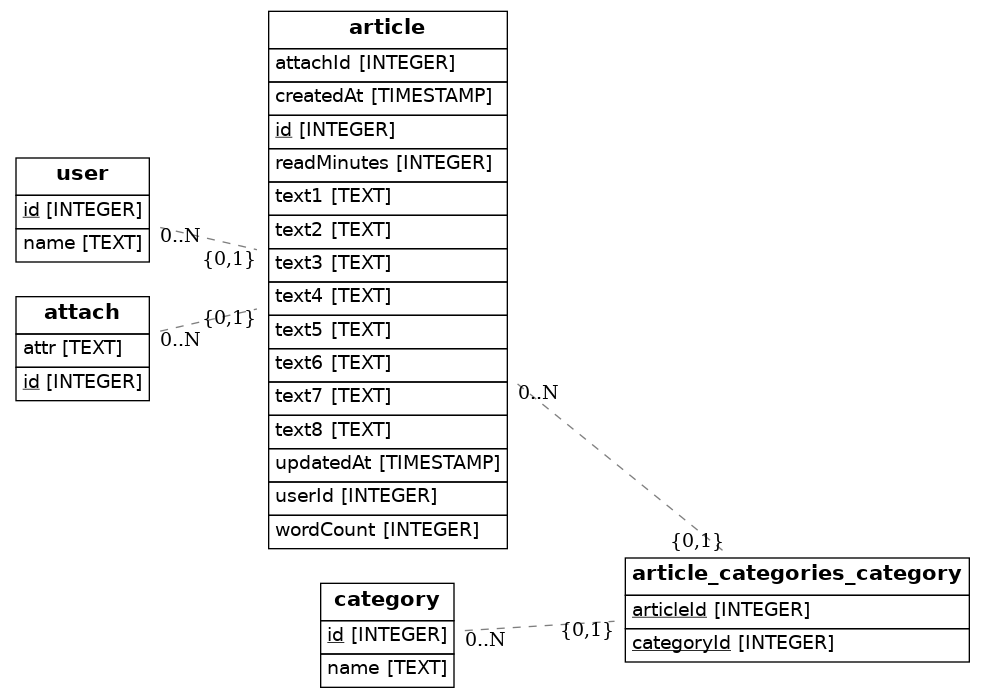
メモリ使用量の検証のためのテーブル
この ER 図は eralchemy というツールで出力できます。
$ eralchemy -i 'postgresql+psycopg2://root:password@localhost:15432/test' \
-o distinct-tables.png \
--include-tables article user category attach \
article_categories_category
TypeORM API のおさらい
TypeORM でデータを取得するとき、大きくわけて2通りの API があります。
Repository API を使うときと Query Builder を使うときで指定できるオプションや生成される SQL が変わってきます。
ページングについて
ドキュメントは Using pagination になります。
TypeORM では次のようにページングには take, skip というオプションを使うことを推奨しています。
const users = await getRepository(User)
.createQueryBuilder("user")
.leftJoinAndSelect("user.photos", "photo")
.skip(5)
.take(10)
.getMany();
ドキュメントから引用します。
takeandskipmay look like we are usinglimitandoffset, but they aren’t.limitandoffsetmay not work as you expect once you have more complicated queries with joins or subqueries. Usingtakeandskipwill prevent those issues.(意訳)
takeとskipはlimitとoffsetと同じようにみえますが、それらは異なるものです。limitとoffsetは結合やサブクエリを伴う複雑なクエリにおいては意図した動作にならないかもしれません。takeとskipはそういった問題を防いでくれます。
本稿では、どういったコードからどのような SQL が発行されるかを調べながら
take/skip と limit/offset の違いについてみていきます。
Select
REPL で実行すると、デバッグ用に SQL も一緒に出力されます。
Repository.find()
まずは結合を伴わない Repository API の find にオプションを指定して実行してみます。 出力される SQL に LIMIT/OFFSET が指定されていることがわかります。
> await getConnection().getRepository(Article).find({take: 3, skip: 10})
> query: SELECT "Article"."id" AS "Article_id", "Article"."wordCount" AS "Article_wordCount", "Article"."readMinutes" AS "Article_readMinutes", "Article"."text1" AS "Article_text1", "Article"."text2" AS "Article_text2", "Article"."text3" AS "Article_text3", "Article"."text4" AS "Article_text4", "Article"."text5" AS "Article_text5", "Article"."text6" AS "Article_text6", "Article"."text7" AS "Article_text7", "Article"."text8" AS "Article_text8", "Article"."createdAt" AS "Article_createdAt", "Article"."updatedAt" AS "Article_updatedAt", "Article"."userId" AS "Article_userId", "Article"."attachId" AS "Article_attachId" FROM "article" "Article" LIMIT 3 OFFSET 10
次に @ManyToMany の categories を結合してみます。
> await getConnection().getRepository(Article).find({relations: ["categories"], take: 3, skip: 10})
query: SELECT DISTINCT "distinctAlias"."Article_id" as "ids_Article_id" FROM (SELECT "Article"."id" AS "Article_id", "Article"."wordCount" AS "Article_wordCount", "Article"."readMinutes" AS "Article_readMinutes", "Article"."text1" AS "Article_text1", "Article"."text2" AS "Article_text2", "Article"."text3" AS "Article_text3", "Article"."text4" AS "Article_text4", "Article"."text5" AS "Article_text5", "Article"."text6" AS "Article_text6", "Article"."text7" AS "Article_text7", "Article"."text8" AS "Article_text8", "Article"."createdAt" AS "Article_createdAt", "Article"."updatedAt" AS "Article_updatedAt", "Article"."userId" AS "Article_userId", "Article"."attachId" AS "Article_attachId", "Article__categories"."id" AS "Article__categories_id", "Article__categories"."name" AS "Article__categories_name" FROM "article" "Article" LEFT JOIN "article_categories_category" "Article_Article__categories" ON "Article_Article__categories"."articleId"="Article"."id" LEFT JOIN "category" "Article__categories" ON "Article__categories"."id"="Article_Article__categories"."categoryId") "distinctAlias" ORDER BY "Article_id" ASC LIMIT 3 OFFSET 10
query: SELECT "Article"."id" AS "Article_id", "Article"."wordCount" AS "Article_wordCount", "Article"."readMinutes" AS "Article_readMinutes", "Article"."text1" AS "Article_text1", "Article"."text2" AS "Article_text2", "Article"."text3" AS "Article_text3", "Article"."text4" AS "Article_text4", "Article"."text5" AS "Article_text5", "Article"."text6" AS "Article_text6", "Article"."text7" AS "Article_text7", "Article"."text8" AS "Article_text8", "Article"."createdAt" AS "Article_createdAt", "Article"."updatedAt" AS "Article_updatedAt", "Article"."userId" AS "Article_userId", "Article"."attachId" AS "Article_attachId", "Article__categories"."id" AS "Article__categories_id", "Article__categories"."name" AS "Article__categories_name" FROM "article" "Article" LEFT JOIN "article_categories_category" "Article_Article__categories" ON "Article_Article__categories"."articleId"="Article"."id" LEFT JOIN "category" "Article__categories" ON "Article__categories"."id"="Article_Article__categories"."categoryId" WHERE "Article"."id" IN (11, 12, 13)
結合したテーブルに対して DISTINCT と共に LIMIT/OFFSET を指定したプレクエリを実行します。 そのプレクエリから取得された主キーを使って Article の Entity を取得していることがわかります。 このため、2回の SQL を実行することになります。
@ManyToOne の user を結合してみます。
> await getConnection().getRepository(Article).find({relations: ["user"], take: 3, skip: 10})
query: SELECT DISTINCT "distinctAlias"."Article_id" as "ids_Article_id" FROM (SELECT "Article"."id" AS "Article_id", "Article"."wordCount" AS "Article_wordCount", "Article"."readMinutes" AS "Article_readMinutes", "Article"."text1" AS "Article_text1", "Article"."text2" AS "Article_text2", "Article"."text3" AS "Article_text3", "Article"."text4" AS "Article_text4", "Article"."text5" AS "Article_text5", "Article"."text6" AS "Article_text6", "Article"."text7" AS "Article_text7", "Article"."text8" AS "Article_text8", "Article"."createdAt" AS "Article_createdAt", "Article"."updatedAt" AS "Article_updatedAt", "Article"."userId" AS "Article_userId", "Article"."attachId" AS "Article_attachId", "Article__user"."id" AS "Article__user_id", "Article__user"."name" AS "Article__user_name" FROM "article" "Article" LEFT JOIN "user" "Article__user" ON "Article__user"."id"="Article"."userId") "distinctAlias" ORDER BY "Article_id" ASC LIMIT 3 OFFSET 10
query: SELECT "Article"."id" AS "Article_id", "Article"."wordCount" AS "Article_wordCount", "Article"."readMinutes" AS "Article_readMinutes", "Article"."text1" AS "Article_text1", "Article"."text2" AS "Article_text2", "Article"."text3" AS "Article_text3", "Article"."text4" AS "Article_text4", "Article"."text5" AS "Article_text5", "Article"."text6" AS "Article_text6", "Article"."text7" AS "Article_text7", "Article"."text8" AS "Article_text8", "Article"."createdAt" AS "Article_createdAt", "Article"."updatedAt" AS "Article_updatedAt", "Article"."userId" AS "Article_userId", "Article"."attachId" AS "Article_attachId", "Article__user"."id" AS "Article__user_id", "Article__user"."name" AS "Article__user_name" FROM "article" "Article" LEFT JOIN "user" "Article__user" ON "Article__user"."id"="Article"."userId" WHERE "Article"."id" IN (11, 12, 13)
@OneToOne の attach を結合してみます。
> await getConnection().getRepository(Article).find({relations: ["attach"], take: 3, skip: 10})
query: SELECT DISTINCT "distinctAlias"."Article_id" as "ids_Article_id" FROM (SELECT "Article"."id" AS "Article_id", "Article"."wordCount" AS "Article_wordCount", "Article"."readMinutes" AS "Article_readMinutes", "Article"."text1" AS "Article_text1", "Article"."text2" AS "Article_text2", "Article"."text3" AS "Article_text3", "Article"."text4" AS "Article_text4", "Article"."text5" AS "Article_text5", "Article"."text6" AS "Article_text6", "Article"."text7" AS "Article_text7", "Article"."text8" AS "Article_text8", "Article"."createdAt" AS "Article_createdAt", "Article"."updatedAt" AS "Article_updatedAt", "Article"."userId" AS "Article_userId", "Article"."attachId" AS "Article_attachId", "Article__attach"."id" AS "Article__attach_id", "Article__attach"."attr" AS "Article__attach_attr" FROM "article" "Article" LEFT JOIN "attach" "Article__attach" ON "Article__attach"."id"="Article"."attachId") "distinctAlias" ORDER BY "Article_id" ASC LIMIT 3 OFFSET 10
query: SELECT "Article"."id" AS "Article_id", "Article"."wordCount" AS "Article_wordCount", "Article"."readMinutes" AS "Article_readMinutes", "Article"."text1" AS "Article_text1", "Article"."text2" AS "Article_text2", "Article"."text3" AS "Article_text3", "Article"."text4" AS "Article_text4", "Article"."text5" AS "Article_text5", "Article"."text6" AS "Article_text6", "Article"."text7" AS "Article_text7", "Article"."text8" AS "Article_text8", "Article"."createdAt" AS "Article_createdAt", "Article"."updatedAt" AS "Article_updatedAt", "Article"."userId" AS "Article_userId", "Article"."attachId" AS "Article_attachId", "Article__attach"."id" AS "Article__attach_id", "Article__attach"."attr" AS "Article__attach_attr" FROM "article" "Article" LEFT JOIN "attach" "Article__attach" ON "Article__attach"."id"="Article"."attachId" WHERE "Article"."id" IN (11, 12, 13)
@OneToMany は User から Article を結合してみます。
> await getConnection().getRepository(User).find({relations: ["article"], take: 3, skip: 10})
query: SELECT DISTINCT "distinctAlias"."User_id" as "ids_User_id" FROM (SELECT "User"."id" AS "User_id", "User"."name" AS "User_name", "User__article"."id" AS "User__article_id", "User__article"."wordCount" AS "User__article_wordCount", "User__article"."readMinutes" AS "User__article_readMinutes", "User__article"."text1" AS "User__article_text1", "User__article"."text2" AS "User__article_text2", "User__article"."text3" AS "User__article_text3", "User__article"."text4" AS "User__article_text4", "User__article"."text5" AS "User__article_text5", "User__article"."text6" AS "User__article_text6", "User__article"."text7" AS "User__article_text7", "User__article"."text8" AS "User__article_text8", "User__article"."createdAt" AS "User__article_createdAt", "User__article"."updatedAt" AS "User__article_updatedAt", "User__article"."userId" AS "User__article_userId", "User__article"."attachId" AS "User__article_attachId" FROM "user" "User" LEFT JOIN "article" "User__article" ON "User__article"."userId"="User"."id") "distinctAlias" ORDER BY "User_id" ASC LIMIT 3 OFFSET 10
query: SELECT "User"."id" AS "User_id", "User"."name" AS "User_name", "User__article"."id" AS "User__article_id", "User__article"."wordCount" AS "User__article_wordCount", "User__article"."readMinutes" AS "User__article_readMinutes", "User__article"."text1" AS "User__article_text1", "User__article"."text2" AS "User__article_text2", "User__article"."text3" AS "User__article_text3", "User__article"."text4" AS "User__article_text4", "User__article"."text5" AS "User__article_text5", "User__article"."text6" AS "User__article_text6", "User__article"."text7" AS "User__article_text7", "User__article"."text8" AS "User__article_text8", "User__article"."createdAt" AS "User__article_createdAt", "User__article"."updatedAt" AS "User__article_updatedAt", "User__article"."userId" AS "User__article_userId", "User__article"."attachId" AS "User__article_attachId" FROM "user" "User" LEFT JOIN "article" "User__article" ON "User__article"."userId"="User"."id" WHERE "User"."id" IN (11, 12, 13)
QueryBuilder.getMany()
Repository API の find オプションには take/skip しか指定できません。
一方で Query Builder を使うと take/skip と limit/offset の両方を使い分けることができます。
まずは結合を伴わないコードから実行してみます。
結合せず take/skip を指定するとき
> await getConnection().getRepository(Article).createQueryBuilder("article").take(3).skip(10).getMany()
query: SELECT "article"."id" AS "article_id", "article"."wordCount" AS "article_wordCount", "article"."readMinutes" AS "article_readMinutes", "article"."text1" AS "article_text1", "article"."text2" AS "article_text2", "article"."text3" AS "article_text3", "article"."text4" AS "article_text4", "article"."text5" AS "article_text5", "article"."text6" AS "article_text6", "article"."text7" AS "article_text7", "article"."text8" AS "article_text8", "article"."createdAt" AS "article_createdAt", "article"."updatedAt" AS "article_updatedAt", "article"."userId" AS "article_userId", "article"."attachId" AS "article_attachId" FROM "article" "article" LIMIT 3 OFFSET 10
結合せず limit/offset を指定するとき
> await getConnection().getRepository(Article).createQueryBuilder("article").limit(3).offset(10).getMany()
query: SELECT "article"."id" AS "article_id", "article"."wordCount" AS "article_wordCount", "article"."readMinutes" AS "article_readMinutes", "article"."text1" AS "article_text1", "article"."text2" AS "article_text2", "article"."text3" AS "article_text3", "article"."text4" AS "article_text4", "article"."text5" AS "article_text5", "article"."text6" AS "article_text6", "article"."text7" AS "article_text7", "article"."text8" AS "article_text8", "article"."createdAt" AS "article_createdAt", "article"."updatedAt" AS "article_updatedAt", "article"."userId" AS "article_userId", "article"."attachId" AS "article_attachId" FROM "article" "article" LIMIT 3 OFFSET 10
Repository API 同様、出力される SQL に LIMIT/OFFSET が指定されていることがわかります。
take/skip と limit/offset の指定でとくに違いはありません。
次に @ManyToMany の categories を結合して確認します。
@ManyToMany の categories を結合して take/skip を指定するとき
> await getConnection().getRepository(Article).createQueryBuilder("article").leftJoin("article.categories", "categories").take(3).skip(10).getMany()
query: SELECT DISTINCT "distinctAlias"."article_id" as "ids_article_id" FROM (SELECT "article"."id" AS "article_id", "article"."wordCount" AS "article_wordCount", "article"."readMinutes" AS "article_readMinutes", "article"."text1" AS "article_text1", "article"."text2" AS "article_text2", "article"."text3" AS "article_text3", "article"."text4" AS "article_text4", "article"."text5" AS "article_text5", "article"."text6" AS "article_text6", "article"."text7" AS "article_text7", "article"."text8" AS "article_text8", "article"."createdAt" AS "article_createdAt", "article"."updatedAt" AS "article_updatedAt", "article"."userId" AS "article_userId", "article"."attachId" AS "article_attachId" FROM "article" "article" LEFT JOIN "article_categories_category" "article_categories" ON "article_categories"."articleId"="article"."id" LEFT JOIN "category" "categories" ON "categories"."id"="article_categories"."categoryId") "distinctAlias" ORDER BY "article_id" ASC LIMIT 3 OFFSET 10
query: SELECT "article"."id" AS "article_id", "article"."wordCount" AS "article_wordCount", "article"."readMinutes" AS "article_readMinutes", "article"."text1" AS "article_text1", "article"."text2" AS "article_text2", "article"."text3" AS "article_text3", "article"."text4" AS "article_text4", "article"."text5" AS "article_text5", "article"."text6" AS "article_text6", "article"."text7" AS "article_text7", "article"."text8" AS "article_text8", "article"."createdAt" AS "article_createdAt", "article"."updatedAt" AS "article_updatedAt", "article"."userId" AS "article_userId", "article"."attachId" AS "article_attachId" FROM "article" "article" LEFT JOIN "article_categories_category" "article_categories" ON "article_categories"."articleId"="article"."id" LEFT JOIN "category" "categories" ON "categories"."id"="article_categories"."categoryId" WHERE "article"."id" IN (11, 12, 13)
Repository API 同様、2回の SQL を実行して Article の Entity を取得していることがわかります。
@ManyToMany の categories を結合して limit/offset を指定するとき
> await getConnection().getRepository(Article).createQueryBuilder("article").leftJoin("article.categories", "categories").limit(3).offset(10).getMany()
query: SELECT "article"."id" AS "article_id", "article"."wordCount" AS "article_wordCount", "article"."readMinutes" AS "article_readMinutes", "article"."text1" AS "article_text1", "article"."text2" AS "article_text2", "article"."text3" AS "article_text3", "article"."text4" AS "article_text4", "article"."text5" AS "article_text5", "article"."text6" AS "article_text6", "article"."text7" AS "article_text7", "article"."text8" AS "article_text8", "article"."createdAt" AS "article_createdAt", "article"."updatedAt" AS "article_updatedAt", "article"."userId" AS "article_userId", "article"."attachId" AS "article_attachId" FROM "article" "article" LEFT JOIN "article_categories_category" "article_categories" ON "article_categories"."articleId"="article"."id" LEFT JOIN "category" "categories" ON "categories"."id"="article_categories"."categoryId" LIMIT 3 OFFSET 10
limit/offset を指定したときは結合したテーブルに対して直接 LIMIT/OFFSET が指定されたものを取得しています。
他の関連 @ManyToOne, @OneToOne, @OneToMany については省略しますが、同様の振る舞いをします。
テーブルの結合の有無によって take/skip と limit/offset の振る舞いが変わってきます。
DISTINCT についての考察
引用した TypeORM のドキュメントにもあったようにテーブルを結合するとき、 DISTINCT を使わないと同じ ID を重複して扱ってしまうケースがあります。
直接 SQL を実行した方がわかりやすいのでやってみましょう。
$ docker-compose exec postgres psql -h localhost -U root test
@ManyToMany の関連がわかりやすいので次のような SQL を考えてみます。
いま Article は3つのカテゴリをもつようなデータになっています。
単純にテーブル結合すると同じ Article の ID が重複して行に現れます。
このデータを単純にページングすることはできません。
test=# SELECT a.id "article id", c.id "category id", c.name
test-# FROM article a LEFT JOIN article_categories_category ac ON ac."articleId"=a.id
test-# LEFT JOIN category c ON c.id=ac."categoryId"
test-# limit 10;
article id | category id | name
------------+-------------+------------
1 | 1 | category-1
1 | 2 | category-2
1 | 3 | category-3
2 | 1 | category-1
2 | 2 | category-2
2 | 3 | category-3
3 | 1 | category-1
3 | 2 | category-2
3 | 3 | category-3
4 | 1 | category-1
TypeORM では結合したデータに対して、 DISTINCT で重複排除した主キーに LIMIT/OFFSET を指定してページングしています。 テーブルを結合した結果、主キーが重複する可能性があることを考慮するのは正しいようにみえます。
しかし、必ずしも主キーが重複するわけではありません。
例えば、 @ManyToOne の user は結合しても Article の ID は重複しません。
test=# SELECT a.id "article id", u.id "user id", u.name
test-# FROM article a LEFT JOIN "user" u ON a."userId"=u.id limit 5;
article id | user id | name
------------+---------+--------
1 | 1 | user-1
2 | 2 | user-2
3 | 3 | user-3
4 | 4 | user-4
5 | 5 | user-5
結合した結果の主キーが一意になるとわかっているのであれば、
take/skip を使わずに limit/offset を使ってもページングの振る舞いは変わりません。
そして、limit/offset を使うとき DISTINCT を使ったプレクエリの実行を排除できるため、
パフォーマンスの側面からみると効率がよくなると言えます。
TypeORM 側から考えると、結合によってどういったデータが取得されるかわからないため、 安全側に寄せてすべての結合を伴う状況に対して DISTINCT を使ったプレクエリを発行しているようにみえます。
TypeORM のページングのまとめ
Count
Select 同様、Count も同じような振る舞いをしています。
Repository.count()
まずは結合を伴わない Repository API の count を実行してみます。 普通のシンプルなカウント文が発行されます。
> await getConnection().getRepository(Article).count()
query: SELECT COUNT(1) AS "cnt" FROM "article" "Article"
10000
次に @ManyToMany の categories を結合してカウントします。
> await getConnection().getRepository(Article).count({relations: ["categories"]})
query: SELECT COUNT(DISTINCT("Article"."id")) AS "cnt" FROM "article" "Article" LEFT JOIN "article_categories_category" "Article_Article__categories" ON "Article_Article__categories"."articleId"="Article"."id" LEFT JOIN "category" "Article__categories" ON "Article__categories"."id"="Article_Article__categories"."categoryId"
10000
@ManyToOne の user を結合してカウントします。
> await getConnection().getRepository(Article).count({relations: ["user"]})
query: SELECT COUNT(DISTINCT("Article"."id")) AS "cnt" FROM "article" "Article" LEFT JOIN "user" "Article__user" ON "Article__user"."id"="Article"."userId"
10000
@OneToOne の attach を結合してカウントします。
> await getConnection().getRepository(Article).count({relations: ["attach"]})
query: SELECT COUNT(DISTINCT("Article"."id")) AS "cnt" FROM "article" "Article" LEFT JOIN "attach" "Article__attach" ON "Article__attach"."id"="Article"."attachId"
10000
@OneToMany は User から Article を結合してカウントします。
> await getConnection().getRepository(User).count({relations: ["article"]})
query: SELECT COUNT(DISTINCT("User"."id")) AS "cnt" FROM "user" "User" LEFT JOIN "article" "User__article" ON "User__article"."userId"="User"."id"
10000
一番最初のシンプルな count() と結合を伴う count() で DISTINCT の有無が異なることがわかります。
QueryBuilder.getCount()
続けて Query Builder を使った場合もみていきます。カウントは take/skip や limit/offset を指定しても無視されるようです。
結合を伴わない QueryBuilder.getCount() を実行します。
> await getConnection().getRepository(Article).createQueryBuilder("article").getCount();
query: SELECT COUNT(1) AS "cnt" FROM "article" "article"
10000
次に @ManyToMany の categories を結合してカウントします。
> await getConnection().getRepository(Article).createQueryBuilder("article").leftJoin("article.categories", "categories").getCount()
query: SELECT COUNT(DISTINCT("article"."id")) AS "cnt" FROM "article" "article" LEFT JOIN "article_categories_category" "article_categories" ON "article_categories"."articleId"="article"."id" LEFT JOIN "category" "categories" ON "categories"."id"="article_categories"."categoryId"
10000
@ManyToOne の user を結合してカウントします。
> await getConnection().getRepository(Article).createQueryBuilder("article").leftJoin("article.user", "user").getCount()
query: SELECT COUNT(DISTINCT("article"."id")) AS "cnt" FROM "article" "article" LEFT JOIN "user" "user" ON "user"."id"="article"."userId"
10000
@OneToOne の attach を結合してカウントします。
> await getConnection().getRepository(Article).createQueryBuilder("article").leftJoin("article.attach", "attach").getCount()
query: SELECT COUNT(DISTINCT("article"."id")) AS "cnt" FROM "article" "article" LEFT JOIN "attach" "attach" ON "attach"."id"="article"."attachId"
10000
@OneToMany は User から Article を結合してカウントします。
> await getConnection().getRepository(User).createQueryBuilder("user").leftJoin("user.article", "article").getCount()
query: SELECT COUNT(DISTINCT("user"."id")) AS "cnt" FROM "user" "user" LEFT JOIN "article" "article" ON "article"."userId"="user"."id"
10000
DISTINCT についての考察
Repository.count() も QueryBuilder.getCount() 結合を伴うときは必ず DISTINCT を使った SQL を生成していることがわかります。SELECT の場合、DISTINCT のプレクエリが実行されるので不要であればなくした方がパフォーマンスの側面から効率がよいことは自明でした。
ここでは COUNT のときもパフォーマンス上のメリットがあるかどうかを考察してみます。
SQL のレイテンシを測るために go-sql-executor というツールを使います。並行数を指定して SQL をリクエストできるので1リクエストを処理するときに遅くないものでも並行で複数のリクエストを処理すると遅くなるケースを確認するときに役立ちます。
普通に COUNT するとき
$ ./bin/sql-executor query -concurrent 40 -repeat 10 -q "SELECT COUNT(id) FROM article"
target:
SELECT COUNT(id) FROM article
basic (msec):
- min : 0.771
- max : 10.137
- mean : 3.973
- median : 3.712
- stddevp: 2.205
- stddevs: 2.208
percentiles (msec):
- p99: 10.092
- p95: 7.800
- p90: 7.054
- p80: 5.633
- p70: 4.981
COUNT(DISTINCT) するとき
$ ./bin/sql-executor query -concurrent 40 -repeat 10 -q "SELECT COUNT(DISTINCT(id)) FROM article"
target:
SELECT COUNT(DISTINCT(id)) FROM article
basic (msec):
- min : 1.080
- max : 18.638
- mean : 4.535
- median : 4.137
- stddevp: 2.969
- stddevs: 2.972
percentiles (msec):
- p99: 16.916
- p95: 9.784
- p90: 7.815
- p80: 6.564
- p70: 5.452
いまサンプルのデータベースには1万件のデータしかないので若干遅くなっている程度ぐらいの差しか出ません。 私が検証した限りでは、データ件数が多いテーブルをカウントすると大きな差になってくる場合があります。
私が開発に関わっているアプリケーションの検証環境では、 200万件ほど入っているテーブルに同様のクエリを実行すると 中央値で約1秒と約8秒ぐらいのレイテンシの差になります。
余談ですが、PostgreSQL では DISTINCT を使ってカウントするとパフォーマンスへの影響が大きいそうです。 カウントするときの DISTINCT のパフォーマンス、ならびにその代替手段についての次の記事が参照されているのをよくみかけます。
開発者が結合されるテーブルによって重複データが含まれるかどうかを知っているなら、 カウントするときに DISTINCT の要否をオプションで指定できるとよさそうです。 その要望の issue は以前からあったのですが、 誰も実装していなかったので実装して Pull Request を送ったものが次になります。
現時点ではまだレビュー中になります。 互換性や Select 系の API の DISTINCT の扱いと区別することを考慮すると、 どう設計するのがよいか、正直なところ、よくわかりません。 マージされないかもしれませんが、議論のたたき台になればと考えています。
まとめ
TypeORM のページングやカウントするときに生成される SQL を確認し、 DISTINCT を伴うクエリのパフォーマンスについて考察しました。
データベースシステム、サーバーのスペック、テーブル定義やデータ件数などによっては、 気にしなくてもパフォーマンスの問題にはならない場合もあると思います。 スロークエリのログなどでみかけたときに TypeORM の振る舞いを確認してみると改善できるかもしれません。